Un déploiement à l’aide de Kubernetes
Lors de la création de notre nouvel outil de nettoyage de données clients, nous avons fait le choix lors d’une livraison pour un client de leur créer une instance spécifique.
Par exemple, le client A ne partagera pas son application de Data cli net avec d’autres clients. Cela prendra la forme d’une URL spécifique à chaque client: client1.dataclinet.fr, client2.dataclinet.fr, etc.
L’objectif de ce process est alors de s’assurer que les données du client lui appartiennent.
Process de livraison :
Cette limitation conduit aux besoins d’agilité dans le déploiement puisqu’il est nécessaire de déployer une instance pour chaque client. Pour cela, nous avons choisi l’architecture : Docker + Kubernetes. L’avantage de cette architecture est l’accélération de l’implémentation de nouveaux clients. En moins de 5 minutes, de nouveaux modules peuvent être déployés et être accessibles sur Internet.
Appel à Empreinte digitale
Manquant de compétences sur la partie Kubernetes, nous avons fait appel à un partenaire local: Empreinte digitale.
Empreinte digitale est une entreprise Angevine experte en hébergement cloud. Leur savoir-faire depuis plus de 25 ans leur permet de garantir une sécurité et une disponibilité tout en étant indépendant. Leurs datacenter sont locaux, ils utilisent des technologies libres et open-sources ce qui correspond aux valeurs d’Effidic.
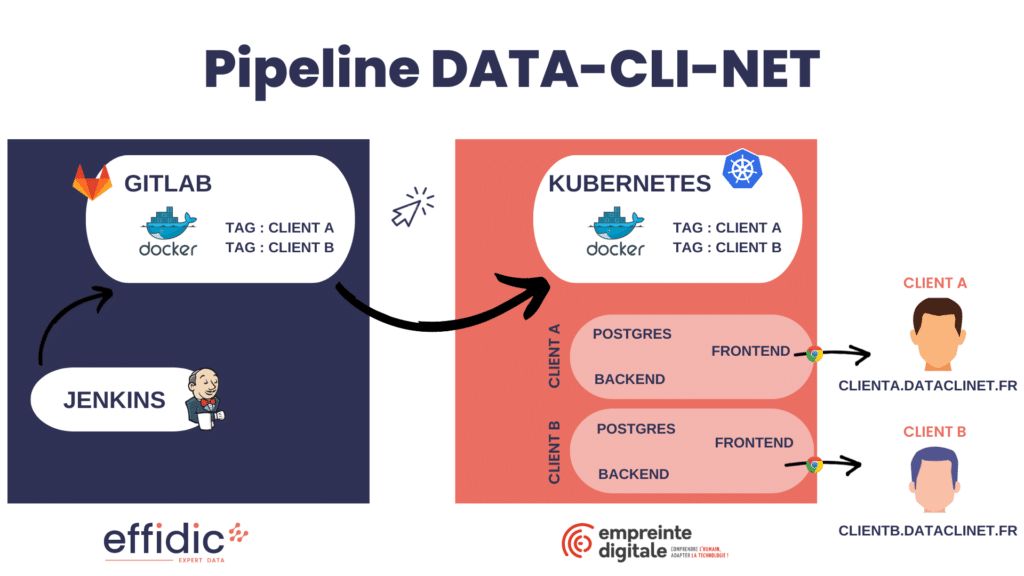
Architecture du déploiement
Lorsqu’une modification est poussée sur la branche de production, Jenkins récupère la nouvelle version, la compile, effectue les tests frontend et backend (sur un serveur remote) afin de s’assurer de la solidité du code.
Si toutes ces étapes sont validées, il construit les images docker front et back en fonction du client.
La BackEnd est le même pour tous les clients mais le front end peut lui être différent.
C’est-à-dire que le client 1 aura le même code en back que le client 2 mais possiblement un code différent en front. On utilise donc les tags des images docker pour différencier les versions par client.
Exemple : Le client 1 aura donc le front end front-end:client1.
Ces images sont ensuite déposées sur gitlab dans le container registry.
D’un autre côté on vient déployer via KubeCtl. Avec une commande, on trigger kubernetes afin qu’ils puissent mettre à jour les images, grâce aux tags il sait lesquels prendre.
En tout le process complet prend environ 5 minutes à se compléter. Avec une interruption de service de maximum 10 secondes au moment de la mise à jour kubernetes. C’est alors un process efficace qui vous prendra peu de temps.