Le métier de consultant data a bien changé !

Que de chemin parcouru !
Nous avons rattrapé le retard avec les métiers du développement web/cloud qui font de la CI/CD depuis plus de 10 ans. Les processus sont industrialisés pour un meilleur partage du code, une meilleure qualité, et enfin de la sérénité lors du passage en production ! L’équipe data n’a pas à rougir et fait bien partie intégrante de la Digital Factory des entreprises, avec les mêmes process et la même rigueur.
Les nouvelles compétences du consultant data :
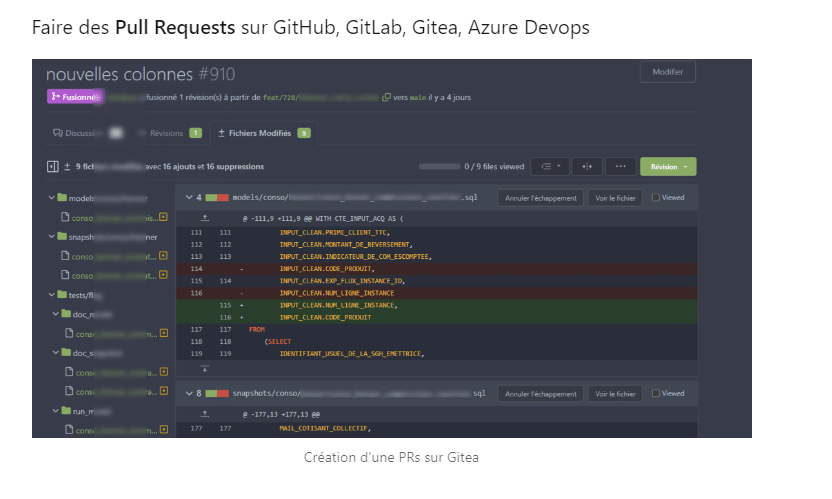
- Connaissance de Git pour le versionning et travail collaboratif. Tout développement s’effectue sur une branche, et tout ajout de code passe par une Pull (ou Merge) Request.
- Notion de Docker. Sans être un expert, il comprend le fonctionnement des images/conteneurs et au besoin sait adapter son Dockerfile au contexte client.
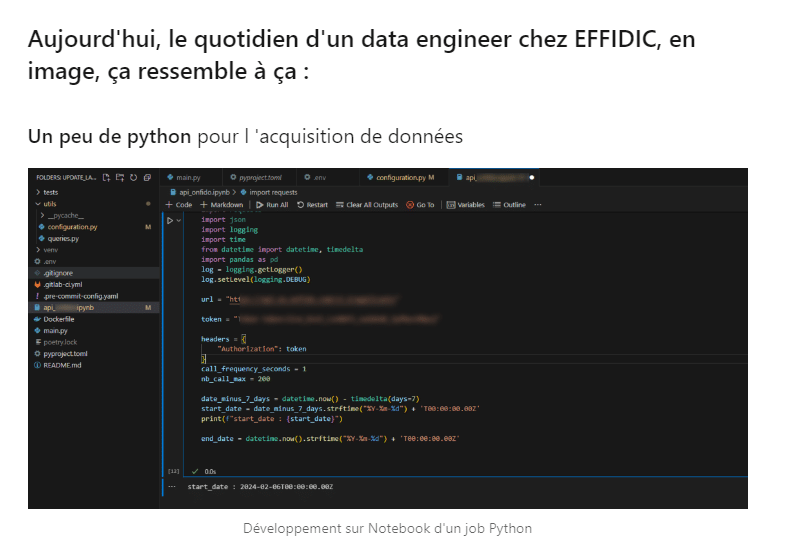
- Connaissance de Python. Dans le monde de la data, savoir l’utiliser est de plus en plus indispensable. Utiliser un virtual env et développer sur Notebook sont la norme.
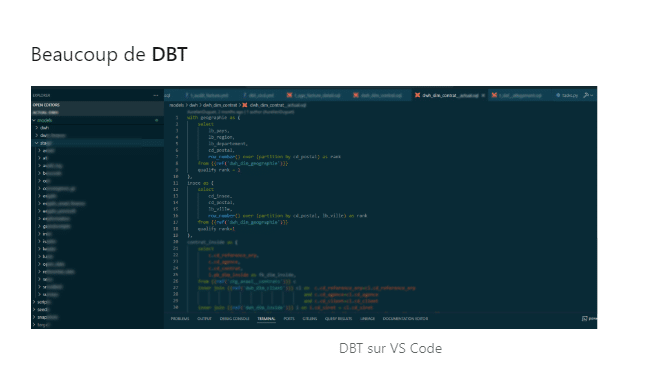
- Le SQL : Compétence qu’il avait normalement déjà, mais avec l’arrivée des Cloud BigQuery et Snowflake, et donc le passage de l’ETL à l’ELT (on utilise la puissance du moteur SQL), ça devient carrément indispensable ! Avec DBT, les WITH (CTEs) et QUALIFY ROW_NUMBER() sont partout 🙂
- Le Finops : Quelques astuces et stratégies sont à connaître pour optimiser le cout de la plateforme data Cloud, entre l’ordonnanceur, l’outil de Data Collect, et le DataWarehouse Cloud. La notion de Slim CI (avec DBT) entre aussi en jeu.
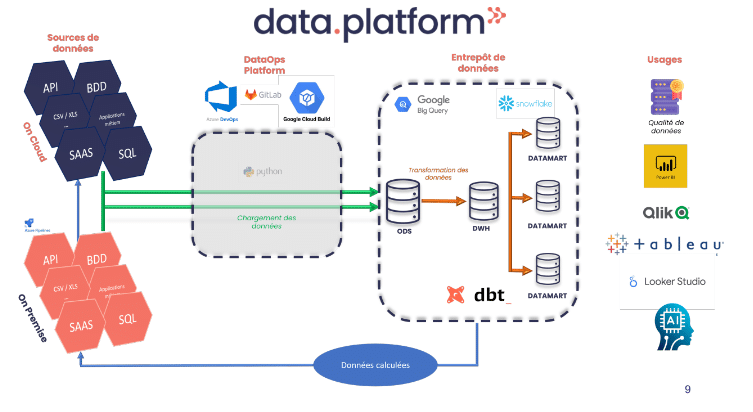
Les atouts de la plateforme data nouvelle générations
Ayant 15 ans d’expériences dans ce que l’on appelait le décisionnel ou la BI (Business Intelligence) à l’époque, c’est un vrai changement. Les ETLs avec des boites à composants à déplacer graphiquement n’ont plus la côte. Gérer ses CREATE TABLE et ses indexation sur son SGBD non plus. Et l’arrivée du Devops dans notre monde très propriétaire / boite noire a insufflé le changement.
A titre personnel, ayant toujours été un peu geek, et parfois frustré de l’utilisation de boites noires, ce changement va dans le bon sens. Mais pour les entreprises c’est aussi le cas !
Lorsque c’est bien géré, une plateforme data nouvelle génération a de nombreux atouts :
- La qualité : tout code en production a été testé automatiquement et relu/validé par des pairs
- La productivité : L’alliance DBT/Cloud Warehouse, c’est l’assurance d’un projet Data qui avance vite
- La performance : les Cloud Warehouse (#Snowflake, #BigQuery, …) offrent des performances d’exécution de requêtes incroyables, ce qui ouvre le champ des possibles
- La disponibilité : Cloud + Devops, c’est le combo pour atteindre les cinq 9 🙂
- La maintenance : Adieu la souffrance des montées de version !
De puissantes opportunités pour les entreprises
Ce renouveau dans la data ingénierie ouvre des horizons pour les dirigeants d’entreprise et DSI qui entendent parler de data partout depuis quelques années, les invitant à considérer ces changements pour rester à la pointe de l’innovation.
Quelques principes :
- Evaluer l’architecture déjà en place chez soi pour savoir si elle saura suivre les nécessaires évolutions de l’entreprise et de son SI ( et en général, tout n’est pas à jeter )
- Réfléchir à la gouvernance à mettre en place pour construire une plateforme de données nouvelle génération
- Savoir choisir les bons outils et les bonnes personnespour mener à bien ce projet, avec la vélocité que l’on est en droit d’attendre avec ces nouvelles technologies
C’est un nouveau monde passionnant qui s’ouvre au domaine de la data ingénierie, et avec la production croissante de données de tous nos équipements, logiciels, usines, c’est un vrai challenge qui nous est proposé !