Identifiez vos risques d’impayés… grâce aux data Open-Source
Le Bulletin officiel des annonces civiles et commerciales (BODACC) assure la publicité des actes enregistrés au registre du commerce et des sociétés. Publiés plusieurs fois par semaine, ces actes permettent de s’informer sur les créations et radiations d’entreprise : ventes et cessions, immatriculations, procédures collectives, dépôt des comptes, etc.
Pour une entreprise, c’est donc une source d’information très pertinente pour anticiper les risque d’impayés d’une entreprise cliente.
En effet, si une entreprise se retrouve en liquidation judiciaire par exemple, vous disposez d’un délai légal de 2 mois pour effectuer la déclaration de créance, à partir de la publication au BODACC de la procédure. Ce qui vous laisse le temps de prendre les dispositions nécessaires… si vous êtes alertés rapidement de cette publication !
Nous allons donc voir à travers cet article, comment (avec Talend) :
- Exploiter les fichiers du BODACC (accessibles en open source)
- Les comparer au fichier de vos clients
- Puis alerter le service facturation dès qu’un client est concerné par une annonce du BODACC.
Etape 1 : se connecter aux bases BODACC
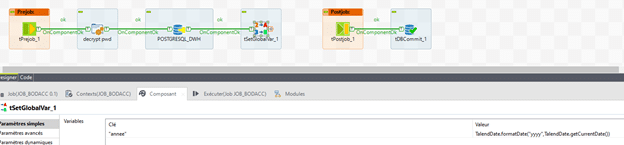
Avant toute chose, nous allons ouvrir une connexion à la base de données à exploiter.
Ceci nous aidera à :
- Enregistrer les informations du BODACC
- puis enregistrer une variable globale de l’année courante, qui nous servira plus tard à scruter le bon dossier sur le serveur FTP des fichiers BODACC.
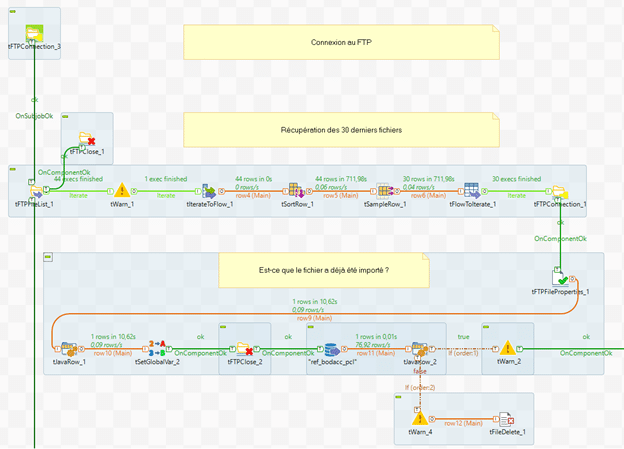
Ouvrons tout d’abord une connexion sur le FTP mis à disposition par le gouvernement.
Les informations de connexion doivent être sollicitées auprès des administrateurs du BODACC
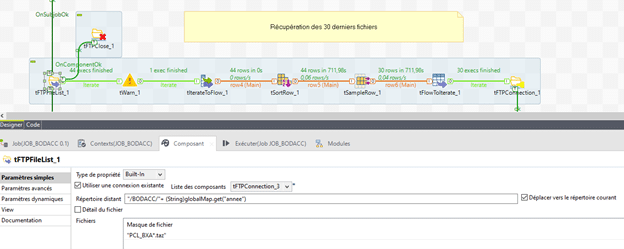
Etape 2 : lister et trier les fichiers disponibles sur le serveur
Pour cela nous utilisons le composant tFTPFileList avec les paramètres suivants :
- Répertoire distant : « /BODACC/ »+ (String)globalMap.get(« année »)
- Masque de fichier : « PCL_BXA*.taz »
Comme vous pouvez le voir, nous réutilisons ici la variable de l’année créée dans le « PreJob »
La connexion est fermée dès que la liste a été récupérée : nous souhaitons ici éviter un « timeout » de la connexion ; une connexion sera rétablie pour chaque étape du flux.
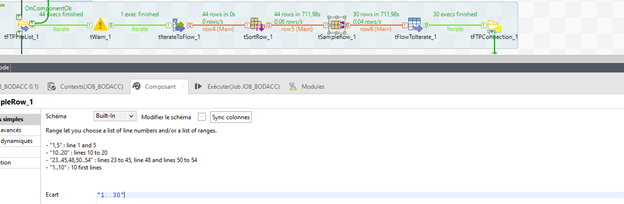
Une fois la liste de fichier récupérée, nous utilisons le composant « tIterateToFlow » afin de trier la liste et ne récupérer que les derniers fichiers envoyés et pas la liste globale.
Nous utilisons ensuite « tSortRow » pour positionner les fichiers les plus récents en premier. Les fichiers étant nommés au format de date US, on réalise un tri décroissant (« desc ») de type « alpha »

Ensuite, il s’agit de limiter le nombre de lignes (donc de fichiers) à récupérer à l’aide du composant « tSampleRow ». Nous souhaitons ici récupérer les 30 premiers fichiers de la liste triée. Il faut donc renseigner « 1..30 » dans le paramètre « Ecart »
Etape 3 : récupérer les informations du fichier
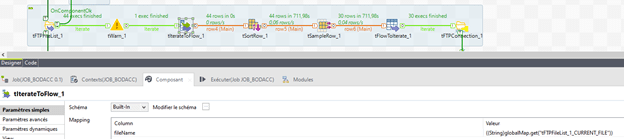
Le composant TFlowToIterate est ensuite ajouté afin de boucler sur chaque fichier de la liste.
Dès le début de la boucle, une nouvelle connexion est créée avec le composant tFTPConnection (la première ayant été fermée après récupération de la liste).
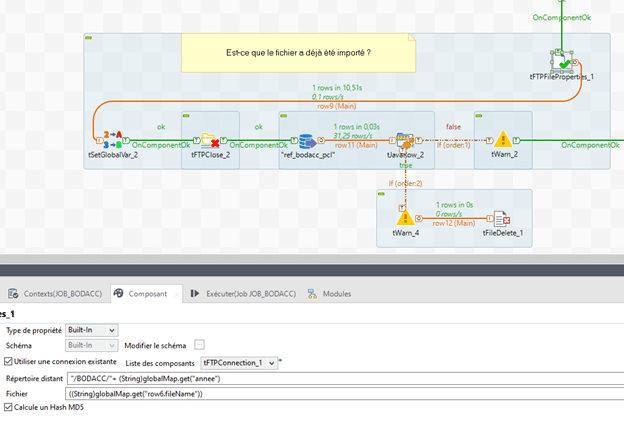
Le composant tFTPFileProperties est ensuite ajouté. Il va permettre de récupérer les informations du fichier et notamment son hash MD5 pour vérifier que le fichier n’a pas déjà été importé.
On réutilise donc la connexion créée juste avant, puis les paramètres suivants sont renseignés :
- Répertoire distant : « /BODACC/ »+ (String)globalMap.get(« année »)
- Fichier : ((String)globalMap.get(« row6.fileName »))
- Le row6.filename correspond au fichier courant dans le flux entre le tSampleRow & tFlowToIterate créé juste avant la boucle.
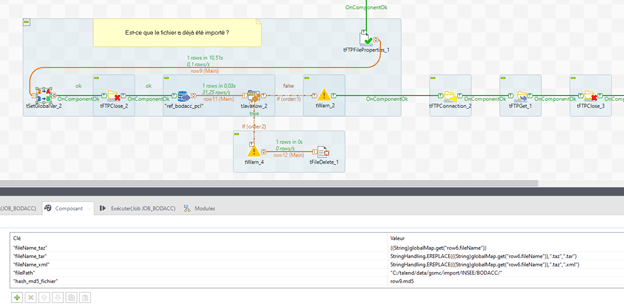
Les noms des fichiers sont ensuite enregistrés (car les fichiers sont doublement compressés) ainsi que le chemin d’extraction et le md5 du fichier dans des variables globales, grâce au composant tSetGlobalVar.
Les paramètres utilisés sont les suivants :
- « fileName_taz » : ((String)globalMap.get(« row6.fileName »))
- « fileName_tar » : StringHandling.EREPLACE(((String)globalMap.get(« row6.fileName »)), ».taz », ».tar »)
- « fileName_xml » : StringHandling.EREPLACE(((String)globalMap.get(« row6.fileName »)), ».taz », ».xml »)
- « filePath » : Le chemin d’extraction du fichier
- « hash_md5_fichier » : row9.md5
- Le row9.md5 correspond au flux entre le tFTPFileProperties & le tSetGlobalVar.
La connexion peut ensuite être fermée
Etape 4 : vérifier que le fichier n’a pas été déjà importé au préalable
Vérifions maintenant que le fichier n’a pas déjà été importé dans notre table.
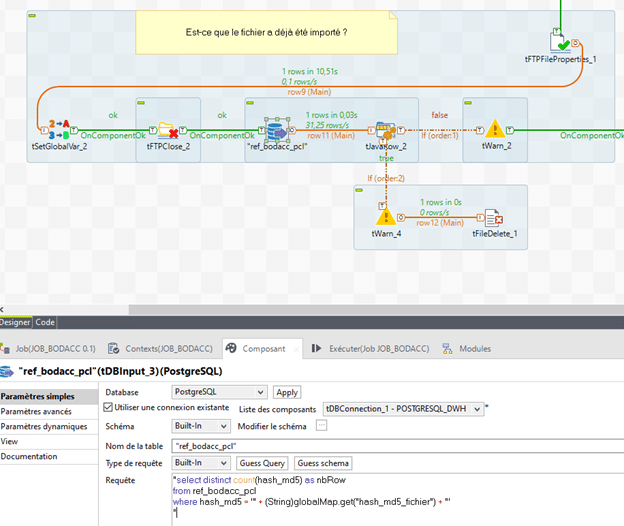
Ici, le composant tDbInput est utilisé pour compter le nombre de lignes où se retrouve le hash md5 du fichier.
S’il y en a plusieurs, le fichier peut être supprimé, sinon le traitement du fichier continue afin de le télécharger, l’extraire et l’importer.
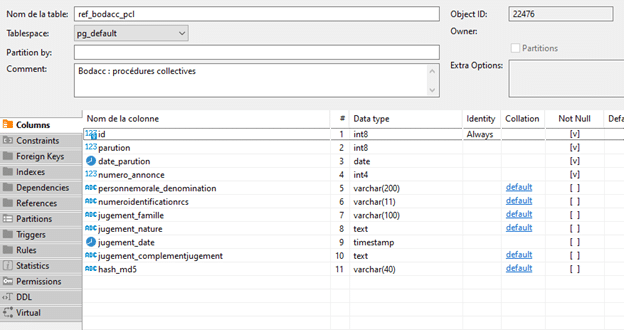
La structure de la table pour accueillir les données du BODACC est la suivante :
La requête suivante est ensuite exécutée dans le tDbInput :
« select distinct count(hash_md5) as nbRow
from ref_bodacc_pcl
where hash_md5 = ‘ » + (String)globalMap.get(« hash_md5_fichier ») + « ‘ »
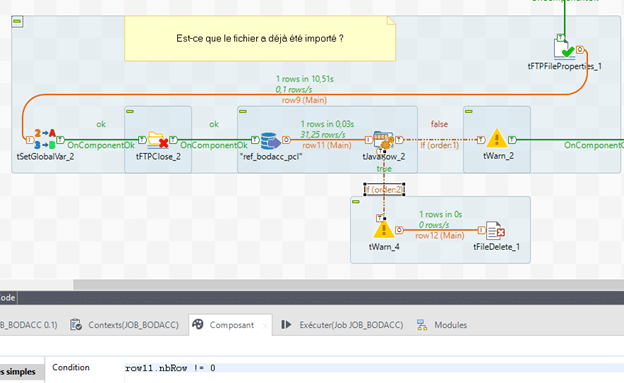
tJavaRow est ensuite ajouté afin d’exécuter la condition pour supprimer le fichier ou l’importer grâce aux deux « If »
Dans le premier cas, s’il y a au moins une ligne, le traitement est stoppé et le fichier supprimé :
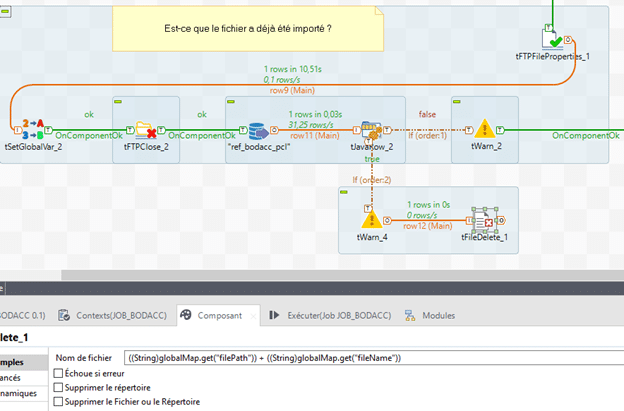
Le tWarn sert à alerter dans la console que le fichier est déjà présent et que le fichier est donc supprimé. Puis le fichier courant est supprimé grâce au tFileDelete, avec comme paramètre pour le nom de fichier : « ((String)globalMap.get(« filePath »)) + ((String)globalMap.get(« fileName »)) »
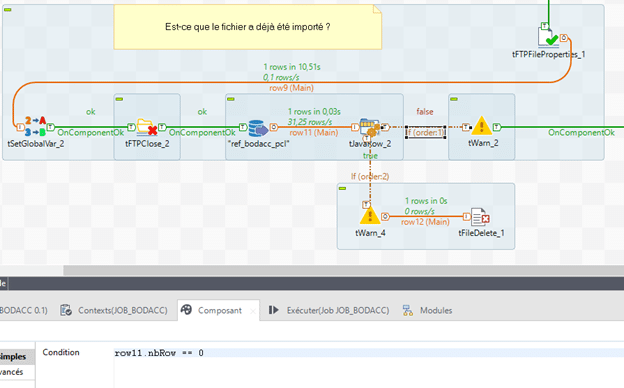
Avec la seconde condition, le traitement continue s’il n’y a pas de ligne en base.
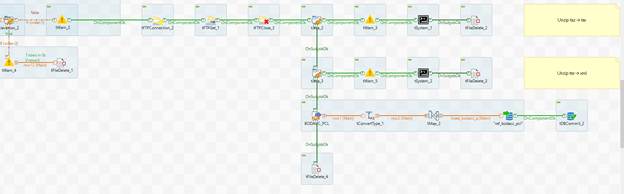
Etape 5 : téléchargement et extraction du fichier
Ouvrons à nouveau une connexion puis téléchargeons le fichier grâce au composant tFTPGet et avec les paramètres suivants :
- Répertoire local : ((String)globalMap.get(« filePath »))
- Répertoire distant : « /BODACC/ »+ (String)globalMap.get(« année »)
- Masque de fichier : ((String)globalMap.get(« fileName_taz »))
La connexion peut être ensuite fermée.
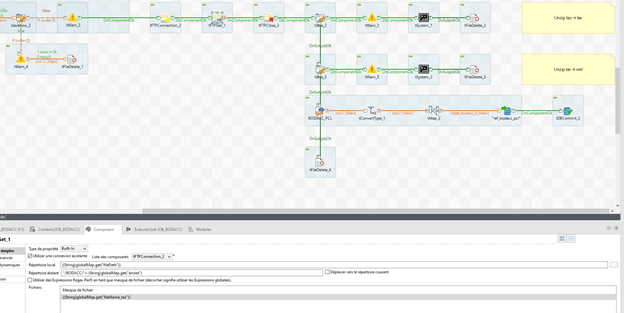
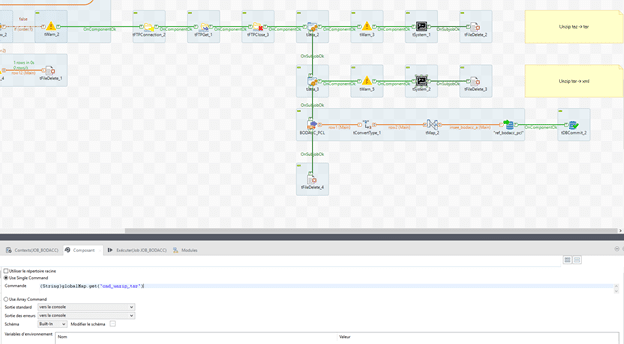
Le fichier étant doublement compressé, il s’agit maintenant de le décompresser. Préparons la première commande dans un tJava. L’extraction se fera avec 7-Zip. Pour ce faire, le code est le suivant :
String cmd = « C:/Program Files/7-Zip/7z.exe x « +((String)globalMap.get(« filePath »)) + ((String)globalMap.get(« fileName_taz »))+ » -aoa -o »+((String)globalMap.get(« filePath »));
globalMap.put(« cmd_unzip_taz », cmd);
La première ligne correspond à la commande pour extraire l’archive, la seconde permet de l’enregistrer dans une variable globale.
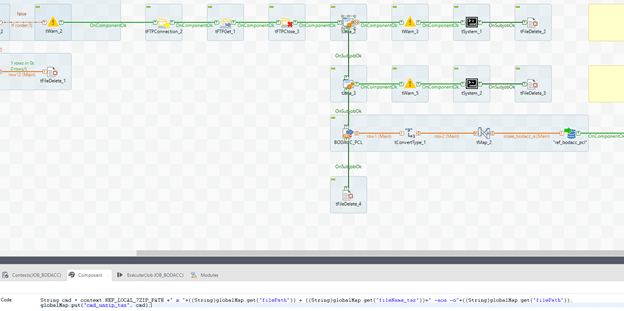
La commande est exécutée via le composant tSystem avec comme paramètre dans « Commande » : « (String)globalMap.get(« cmd_unzip_taz ») »
L’ancienne archive avec un tFileDelete peut être supprimée, avec comme paramètre dans « Nom de fichier » : ((String)globalMap.get(« filePath »)) + ((String)globalMap.get(« fileName_taz »))
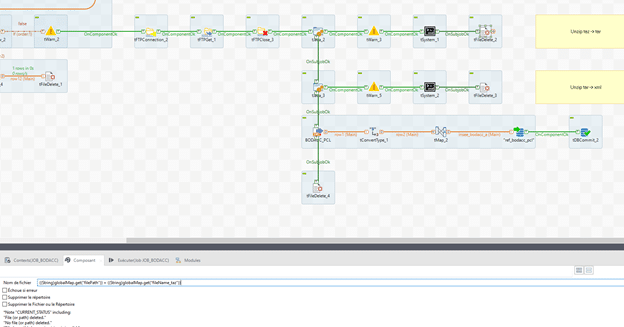
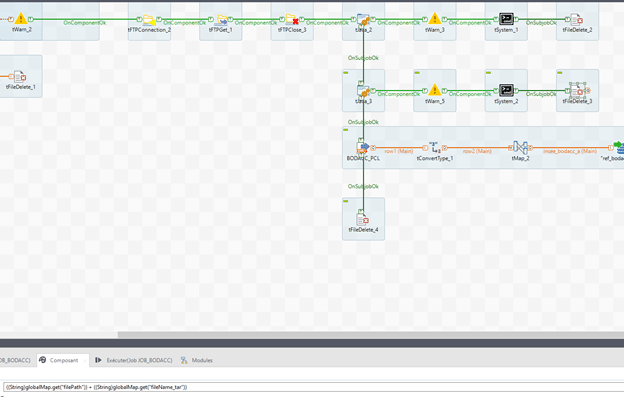
Nous avions un fichier « .taz », nous voilà maintenant avec un fichier « .tar ».
Nous allons répéter l’opération pour extraire de nouveau l’archive :
Il suffit de préparer de nouveau une commande avec le tJava :
String cmd = context.REP_LOCAL_7ZIP_PATH + » x « +((String)globalMap.get(« filePath »)) + ((String)globalMap.get(« fileName_tar »))+ » -aoa -o »+((String)globalMap.get(« filePath »));
globalMap.put(« cmd_unzip_tar », cmd);
Puis encore une fois, avec le tSystem, exécuter la commande avec comme paramètre de « Commande » :
(String)globalMap.get(« cmd_unzip_tar »)
L’archive est ensuite supprimée avec le tFileDelete, avec en paramètre pour « Nom de fichier » : « ((String)globalMap.get(« filePath »)) + ((String)globalMap.get(« fileName_tar »)) »
Etape 6 : insertion des données en base
Maintenant que le fichier .xml est prêt, nous pouvons l’insérer en base de données.
Utilisons le composant « TFileInputXML », paramétré de cette façon :
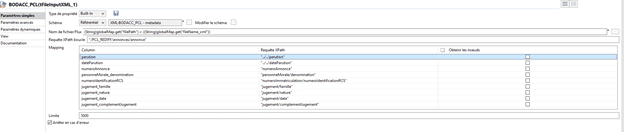
Ajoutons le composant « tConvertType » en cochant les cases « Conversion automatique » & « Définir les valeurs vides comme Null avant de convertir » :
Il convient ensuite d’ajouter un tMap, afin de s’assurer que le champ « numeroIdentificationRCS » n’est pas null.
Il correspond au N° de Siren de l’entreprise, qui sera utilisé afin de comparer les données à notre base client.
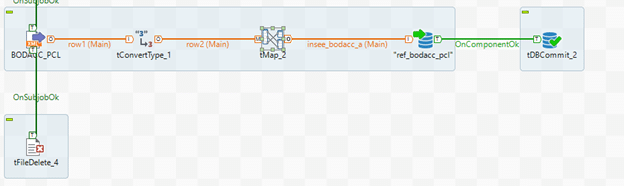
La condition « ! Relational.ISNULL(row2.numeroIdentificationRCS) » est ajoutée.
Le hash md5 correspond au hash du fichier, utilisé précédemment pour vérifier qu’il n’ait pas déjà été importé.
Puis les champs sont formatés et mappés de cette façon :
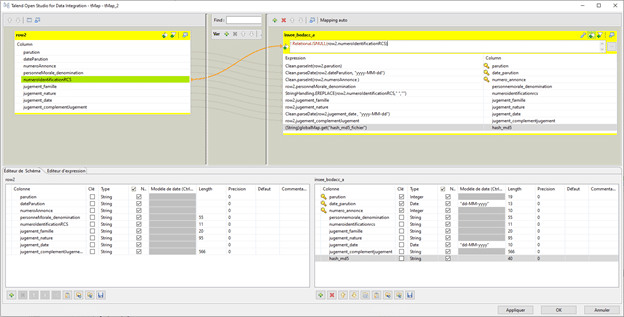
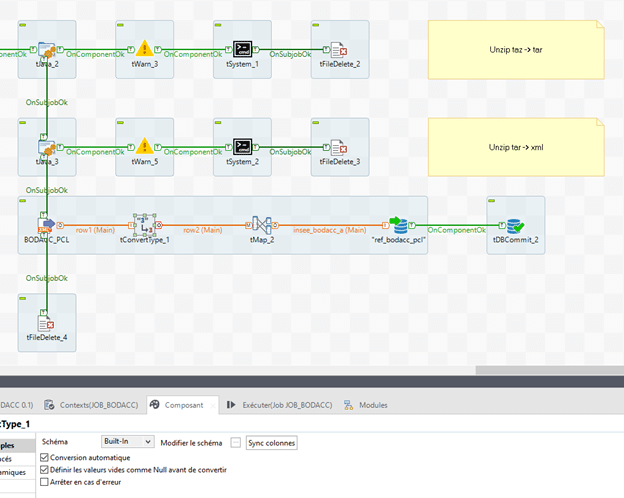
La base de données est insérée dans la table « ref_bodacc_pcl » avec un tDbInput.
La transaction est commit, et le fichier xml supprimé, avec un tFileDelete qui prend en paramètre pour « Nom de fichier » : (String)globalMap.get(« filePath »)
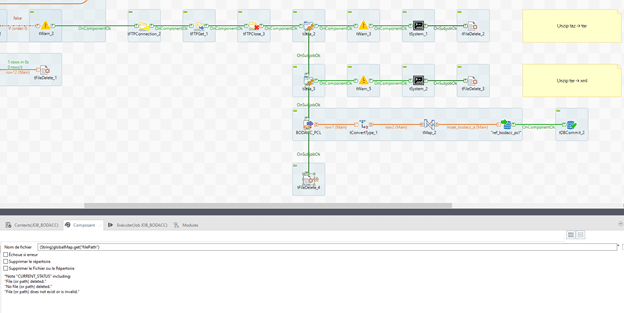
Etape 7 : comparaison avec la base client et mise à jour
Le premier sous-job est terminé, nous pouvons passer maintenant à la comparaison avec notre base client.
Ajoutons un tDbInput de notre base client, plus précisément de notre base de personnes morales.
Nous aurons besoin :
- de son identifiant (id) en cas de mise à jour en base
- de son n° de Siren pour pouvoir comparer avec le BODACC
- de sa raison sociale pour le mail
- et enfin un champ « risque_financier » préalablement créé sur la table.
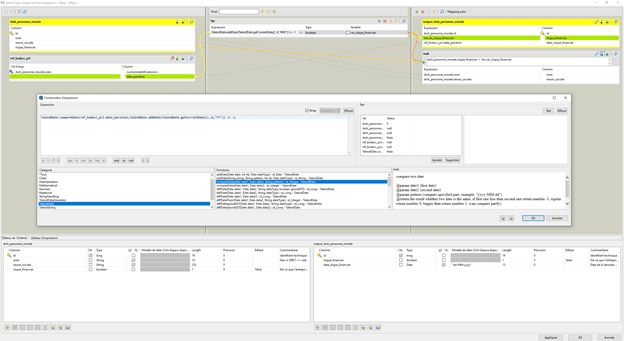
Un tMap est ensuite connecté à notre premier tDbInput.
Un tDbInput est utilisé à nouveau : il contient notre table « ref_bodacc_pcl » qui doit être également lié au tMap.
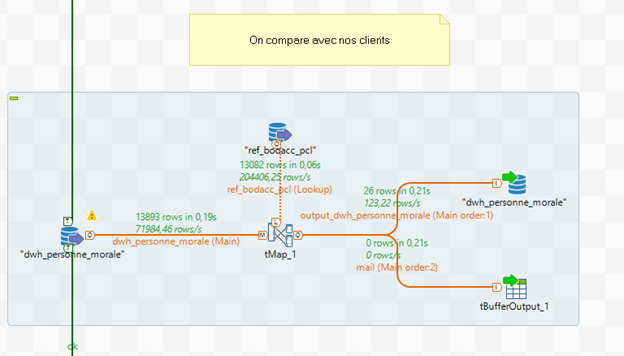
Dans le tMap, la liaison de type « Inner Join » est faite entre la table de personne morale & la table ref_bodacc_pcl sur le Siren & le numéro d’identification RCS.
Puis une variable de type booléen est créée : TalendDate.compareDate(ref_bodacc_pcl.date_parution,TalendDate.addDate(TalendDate.getCurrentDate(),-6, »MM »)) != -1
La fonction TalendDate.compareDate() permet de vérifier si la première date, qui correspond à la date de parution de bodacc est antérieure à la date du jour – 6 mois. Autrement dit, il convient de vérifier qu’il n’y a pas eu de parution au BODACC pour cette entreprise lors des 6 derniers mois. Cela permet d’ignorer de potentielles annonces non récentes.
Deux sorties sont ensuite créées :
- la première permet de mettre à jour la table de personne morale.
Le champ booléen « risque_financier » et le champ date_risque_financier qui enregistre la dernière parution au bodacc, sont mis à jour. Nous pouvons ajouter également l’id enregistré en clé pour permettre la mise à jour ensuite.
- La seconde sortie permet d’envoyer une alerte mail au service financier : nous aurons besoin du Siren et de la raison sociale de l’entreprise.
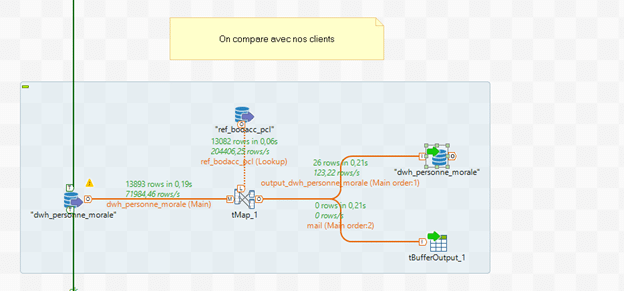
Un composant tDbOutput est créé, avec comme paramètre sur « Action sur les données » : « UPDATE », ce qui permet de mettre à jour la table « personne morale ». Ce composant est ensuite relié à la première sortie de mise à jour du flux.
L’installation d’un tBufferOutput permet d’envoyer l’alerte. Ce composant est lié avec la deuxième sortie, appelé mail ci-dessus.
Etape 8 : création de l’alerte e-mail
Le second sous-job est terminé, nous pouvons maintenant nous occuper d’alerter le service financier (ou tout autre service pertinent).
Un composant tBufferInput permet de récupérer les données envoyées précédemment, ainsi qu’un composant tSendMail qui enverra un mail pour chaque ligne passée dans le tBufferOutput.
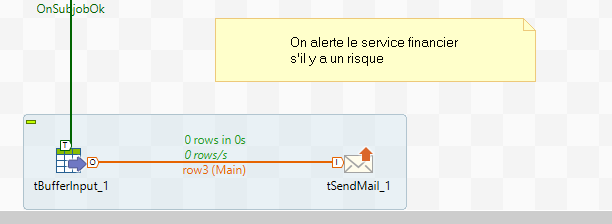
Il nous reste donc à configurer le tSendMail avec nos paramètres SMTP, ainsi que les destinataires.
Puis le format du mail peut être créé.
Pour plus de simplicité pour les destinataires du mail, une URL renvoie directement sur la page liée à la société :

Le job est maintenant terminé et complet ! Il suffit maintenant de planifier le job chaque jour, par exemple, pour avoir l’information quotidiennement.
À partir de maintenant, lorsqu’un risque financier sur un de vos clients ou partenaires surgira, vous en serez tout de suite informé !