Data Build Tool : l’outil du moment pour créer une architecture data performante.
Qu’est-ce que Data Build Tool (DBT) ?
Il est difficile d’expliquer ce logiciel sans trop entrer dans les détails techniques (ou sans l’utiliser !). Voici néanmoins quelques-unes de ses caractéristiques.
Data Build Tool (DBT) est un outil qui permet aux spécialistes data de transformer leurs données au sein-même de leur entrepôt de données (Data Warehouse). L’outil, créé par Fishtown Analytics, est proposé en Open Source et en version cloud (DBT cloud).
Il intervient notamment dans le processus ELT (Extract, Load and Transform) bien connu des développeurs data. Il correspond plus précisément au « T » (Transform) puisque son objectif est de transformer les données directement au sein du Data Warehouse.
DBT + Cloud Datawarehouse : la combinaison gagnante
Le SQL, langage de prédilection lorsqu’il s’agit de manipuler des données, bénéficie d’un récent retour en force. Porté par des plateformes cloud qui le mettent en avant, il est le langage indispensable lorsque l’on veut mettre en place un entrepôt de données.
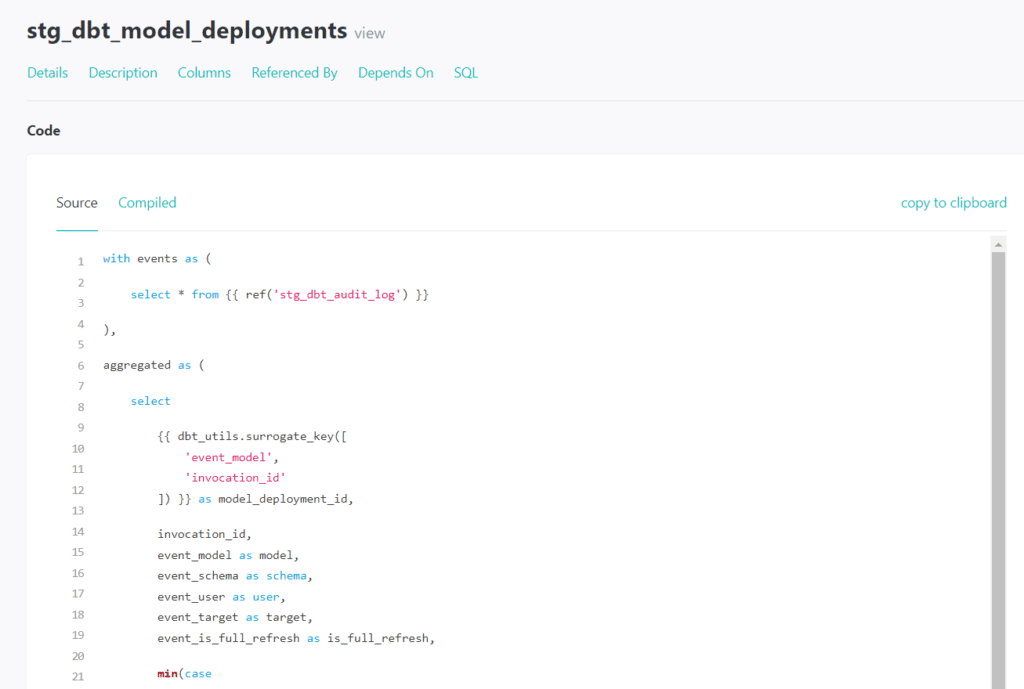
L’emploi du langage SQL, associé au langage templating jinja, simplifie l’utilisation de DBT. En effet, cette combinaison permet l’écriture d’un code plus modulaire, l’utilisation de variables et d’ajouter des structures de contrôle.
De plus, son utilisation sur un Cloud Datawarehouse tel que Snowflake ou Google Big Query permet une productivité largement accrue : spécifier, c’est coder !
Pourquoi utilisons-nous DBT chez Effidic ?
Cet outil permet de structurer l’ensemble des transformations SQL d’un projet DATA/BI.
Plutôt que d’abstraire ce langage en des boîtes « drag and drop » plus ou moins sophistiquées et complexes, DBT a pris le parti de structurer l’écriture de ce langage pour en dégager toute sa puissance.
Lorsque l’on utilise DBT, on écrit ni plus ni moins que des « SELECT » en SQL. DBT se charge de les matérialiser en vues, en tables, et de faire le lien entre toutes les requête « SELECT » qui auront été écrites.
Les 3 principaux intérêts de DBT sont les suivants :
- Être capable d’exécuter les instructions SQL, dans l’ordre, à partir de tout le SQL qui aura été écrit (en détectant au passage, les boucles éventuelles qui auront été écrites par un développeur distrait…)
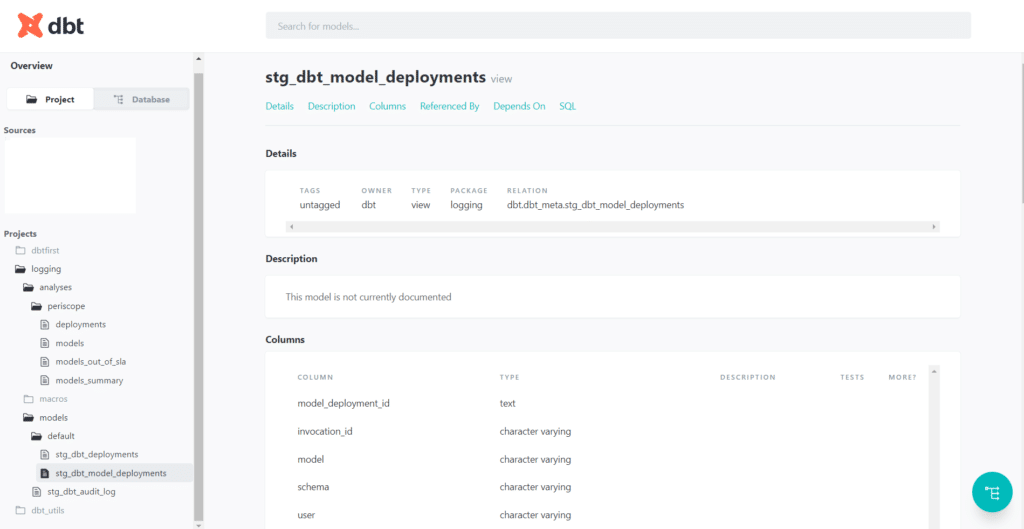
- Générer une documentation vivante, des transformations qui ont lieu dans le DWH. Cette documentation, très visuelle peut être mise à disposition des métiers pour qu’ils trouvent en autonomie la réponse à leur question sur la traçabilité des données et le Data Lineage
- Faciliter les études d’impact, grâce aux graphes de dépendances des tables qui sont générés avec la documentation
